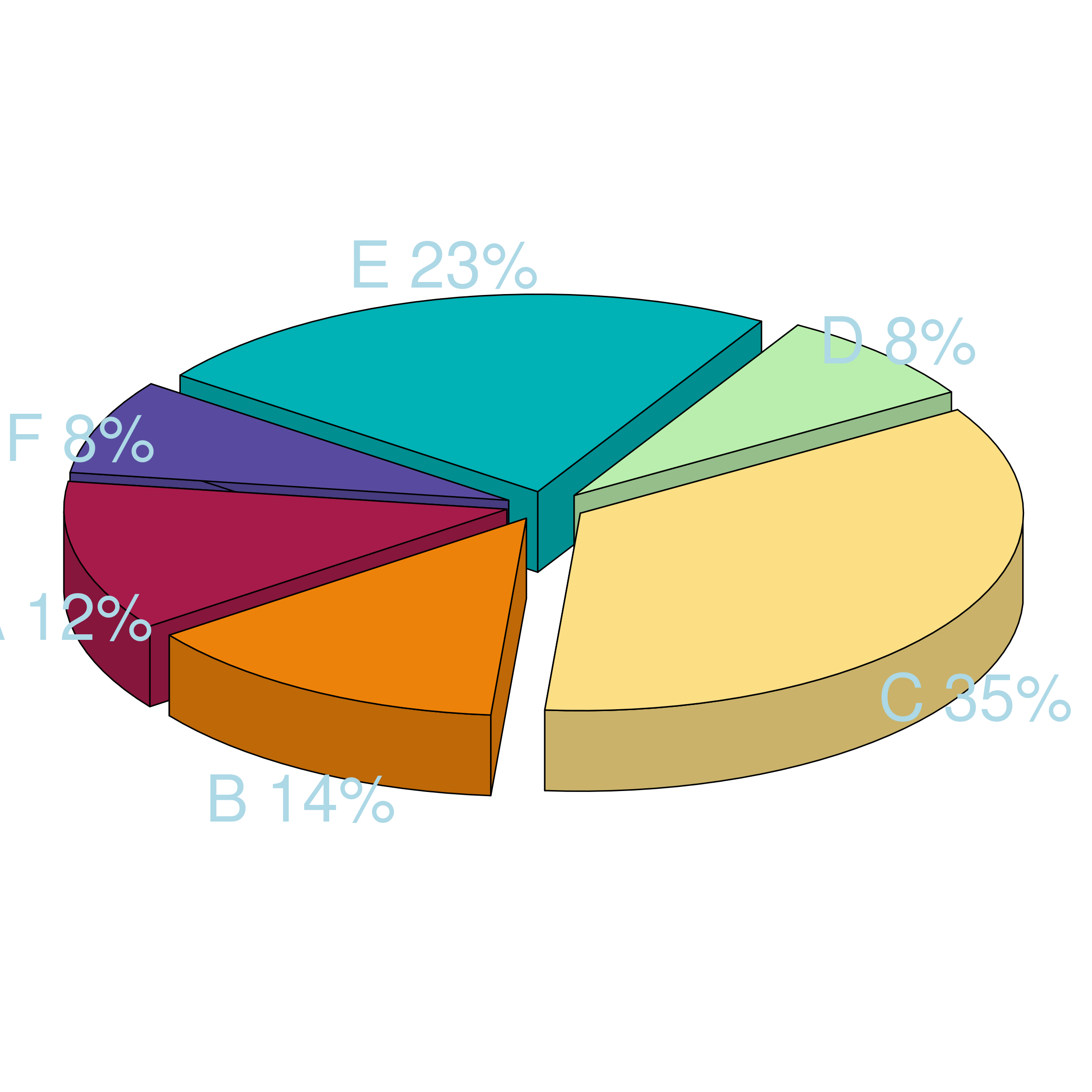
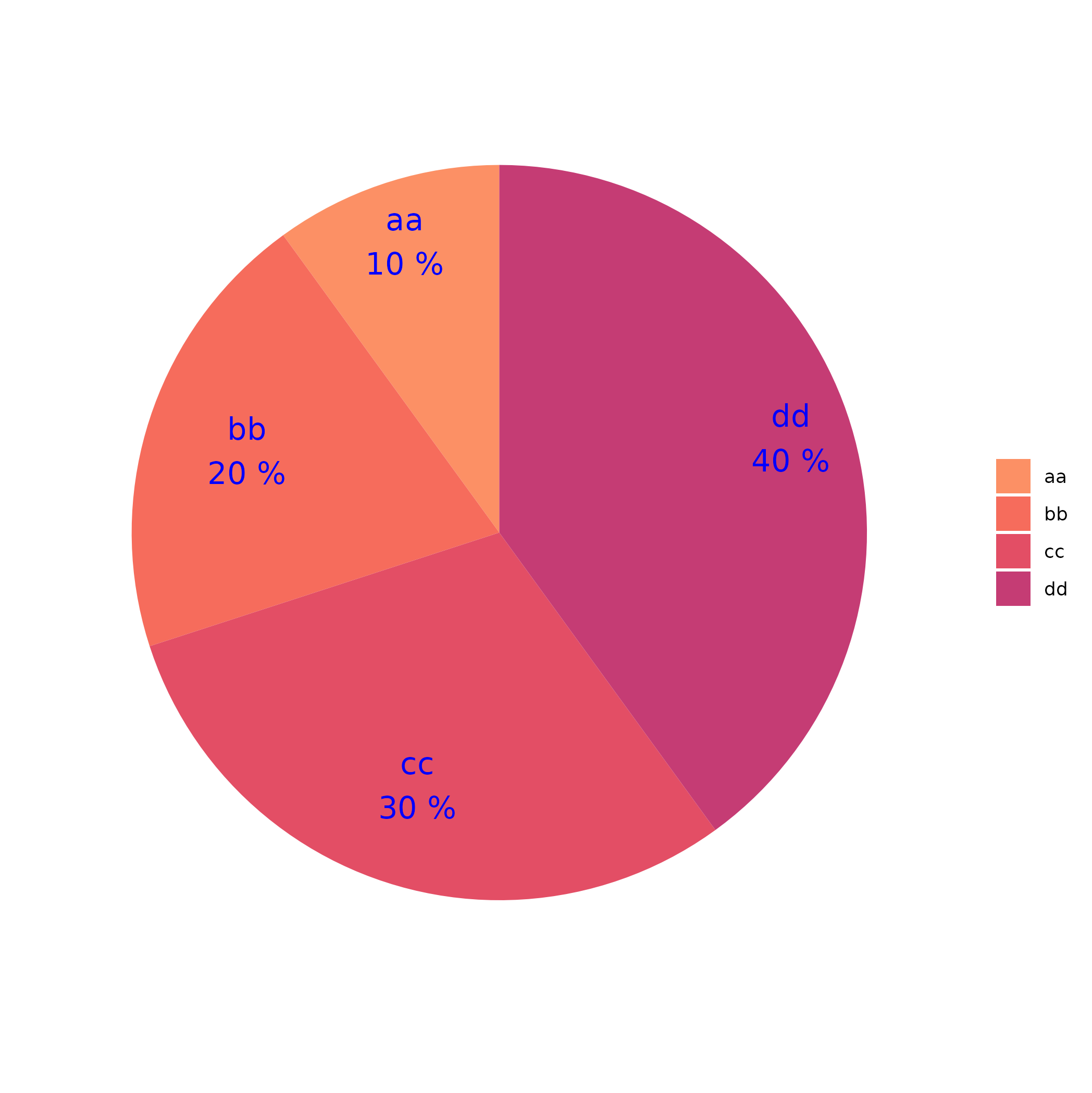
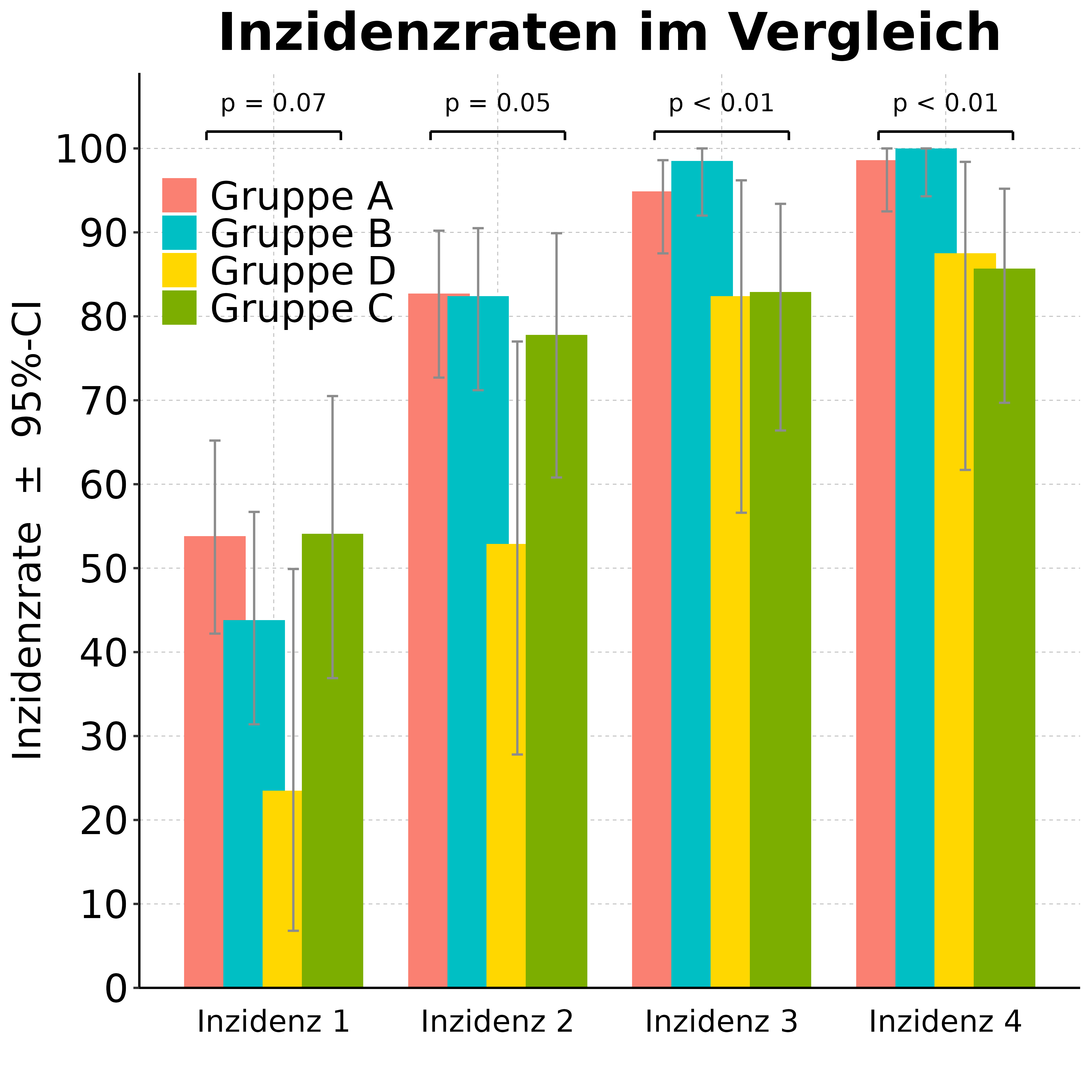
Eine Grafik für Inzidenzraten (mehrere auf einen Blick) bei einer 4-fach Gruppierung
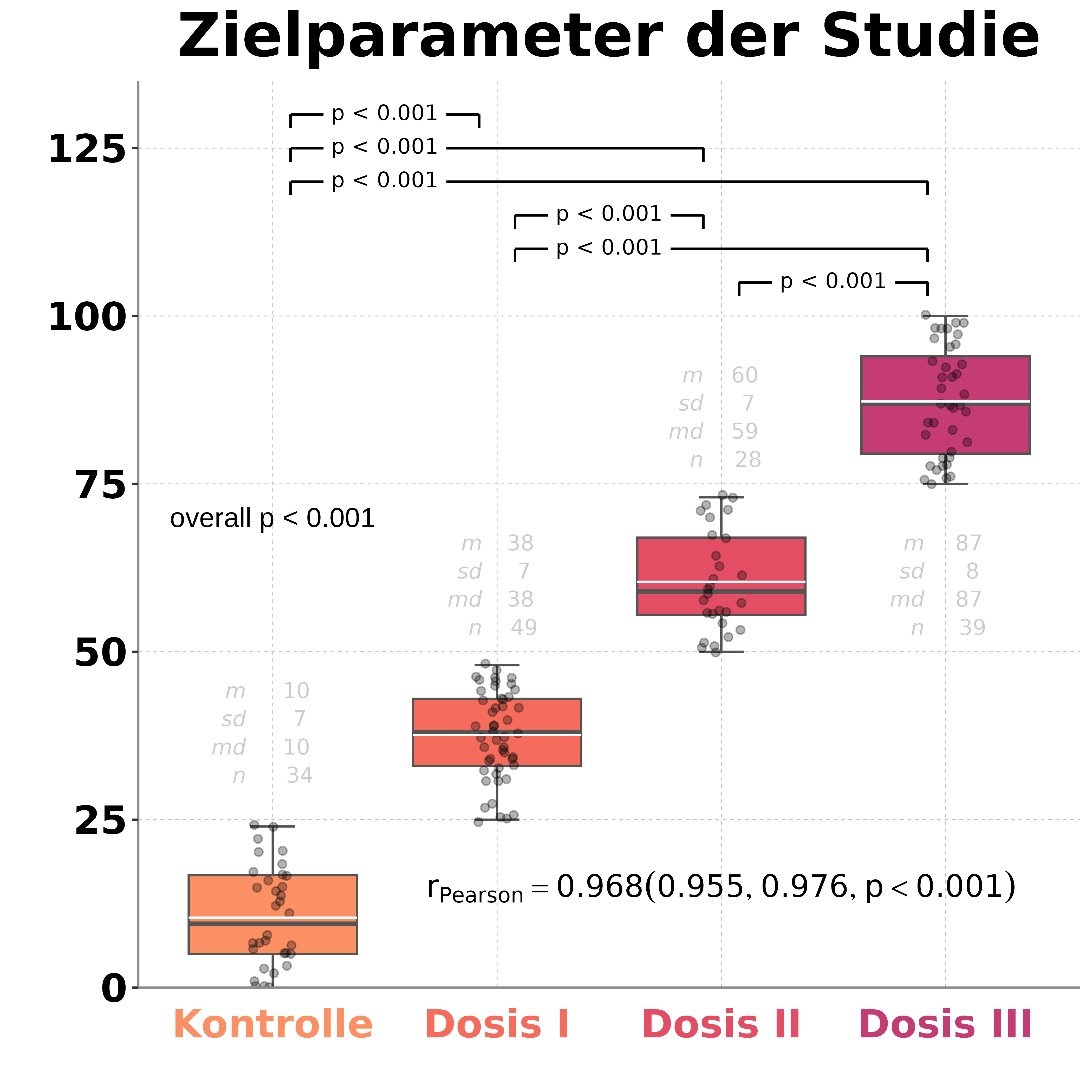
Wie kann man genau eine Inzidenzrate in Säulen darstellen, wenn man gleichzeitig mehrere Gruppierungen hat?Mittels Säulen läßt sich eine Inzidenz vergleichsweise gut darstellen, insbesondere wenn man an Störgrößen interessiert ist (in diesem Fall waren dies Vorerkrankungen). Man möchte die Frage klären, ob die jeweilige Gruppierung (Vorerkrankung) prädiktiv ist mit Blick auf das Ziel (eine Komplikation während der OP möglichst nicht erwarten zu müssen). Kurzgefaßt lautete das Ziel, ob Vorerkrankte unter einem erhöhten Risiko während der OP stehen. Die Grafik ist mit ggplot2 erstellt, der p-Wert ist ein zweiseitiger und exakter 2 x 2-Fisher-Test (in R ist das "fisher.test", der p-Wert kommt aus einer 2 x 2 Tafel). Die Abbildung zeigt, dass nur Diabetiker ('metabolic') unter einem erhöhten Komplikationsrisiko stehen (p < 0.05) und man dies für Patienten mit Problemen der Leber oder Niere hier nicht zeigen konnte (das war fallzahlbedingt). 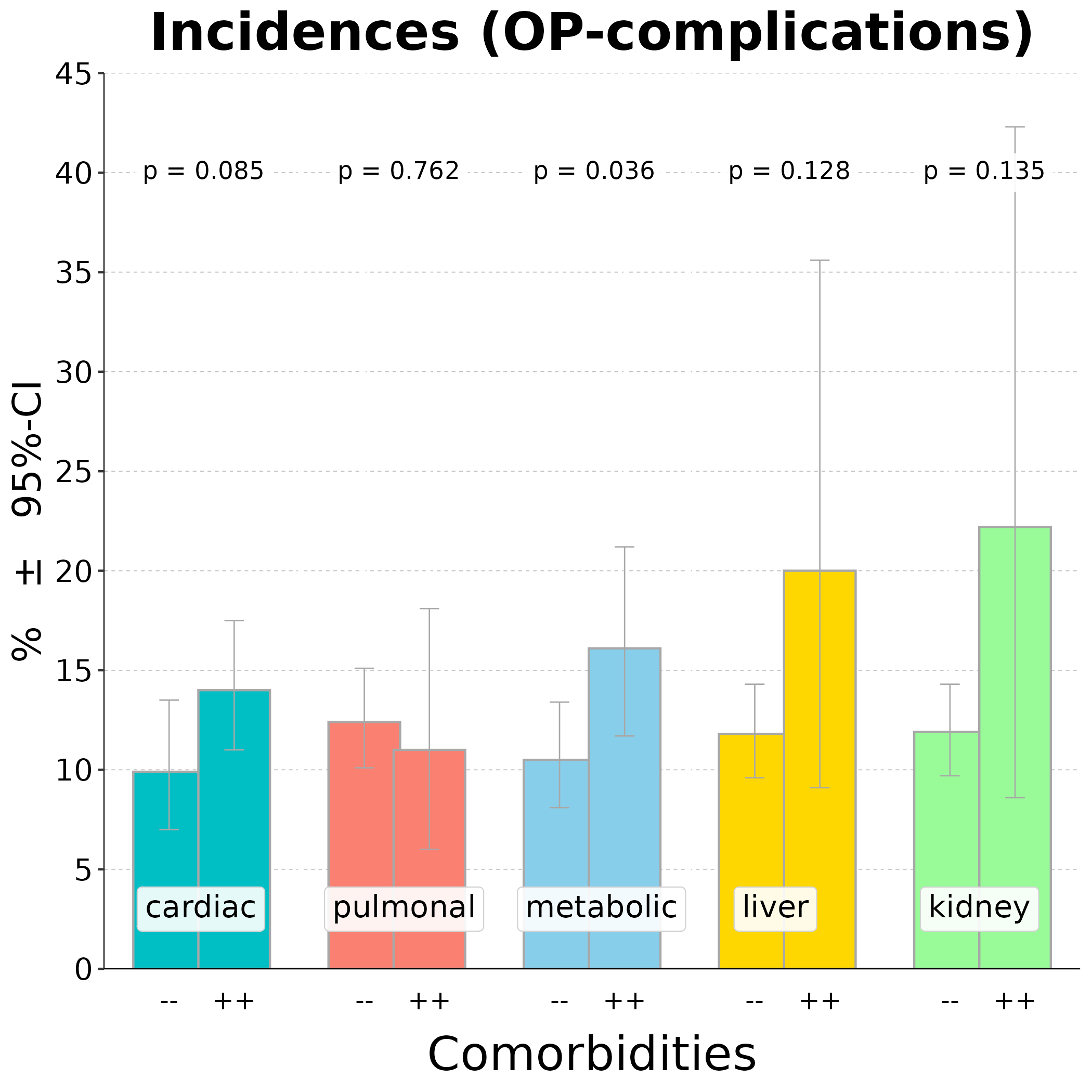 FazitEine Inzidenzrate, die man in verschiedensten Gruppen sehen möchte, läßt sich durchaus komprimiert darstellen, auch wenn vergleichsweise viele Untergruppen vorliegen und man die p-Werte auf einen Blick haben möchte. Man könnte dann im Anschluss schauen, ob die Kovariaten insgesamt mit den Inzidenzen korrelieren und beispielsweise eine logistische Regression quasi als Overall-Test rechnen. |